Making 'Making Legible' Legible
Finding latent relationships within a corpus
With the eventual goal of uncovering a geneaology across the texts, the current iteration explores similarity through document-level and sentence-level comparisons. How much legibility of the text is relevant to the user at different scales of comparison? How do they move from examining all documents to a pair of documents to the sentences within a pair?
Role: data processing and analysis, design, development
Tools: Node.js, d3.js, various NLP libraries, MongoDB
Source text written by Patrick Burke, an architect and urbanist
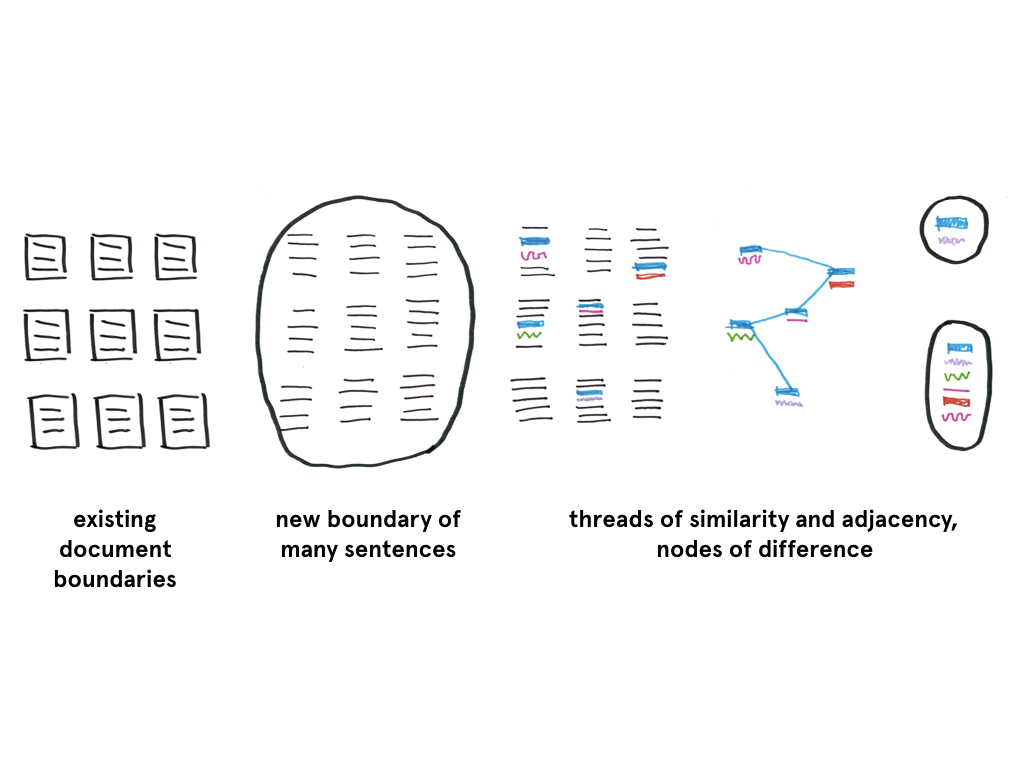
While working across 300,000 words and 650 documents, the project attempts to find latent relationships across the traditional folder-document-sentence structure. Yet, the challenge became how to effectively represent these new relationships outside of this structure.
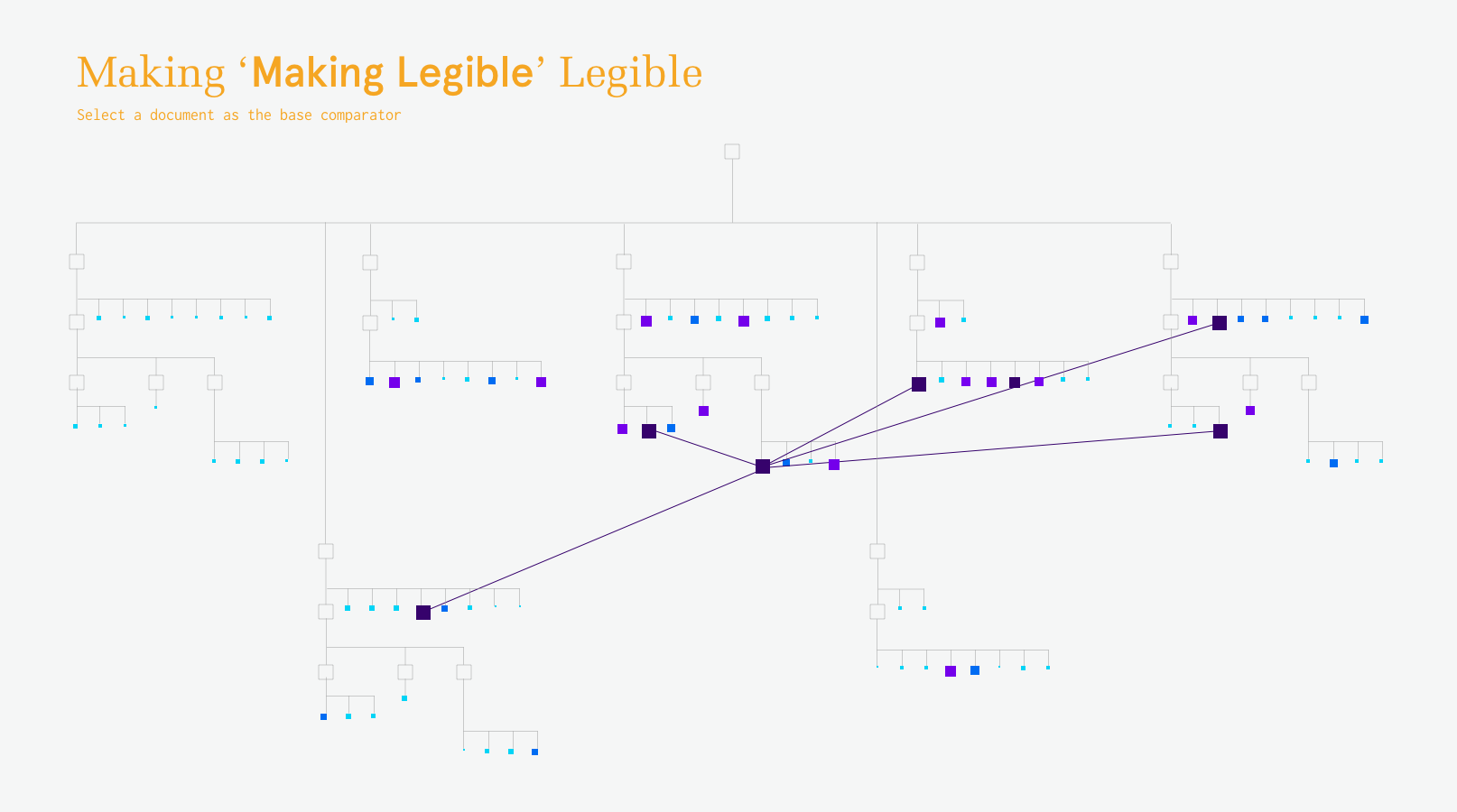
Geneology
When hovering on a document, the similarity to other documents is shown by size and color, with most similar being the largest and most purple.

Cross Document Comparison
Documents are compared to all other documents at the sentence level. Each compared document is represented by a pixel-array in which each sentence in the document-pair is compared using the dice co-efficient method. When dominant diagonals are evident, it indicates a high level of similarity within a portion of two documents.

Inspection
A document-pair comparison can be isolated and user can read the constituent sentences when hovering. This raises the question of what use is the investigation if the readable sentences are buried so deep in the interaction/piece? On one hand, with 680 documents, it’s imposible to get a sense of the ‘whole picture’ without some form of abstraction. But how can the abstraction still be relevant?

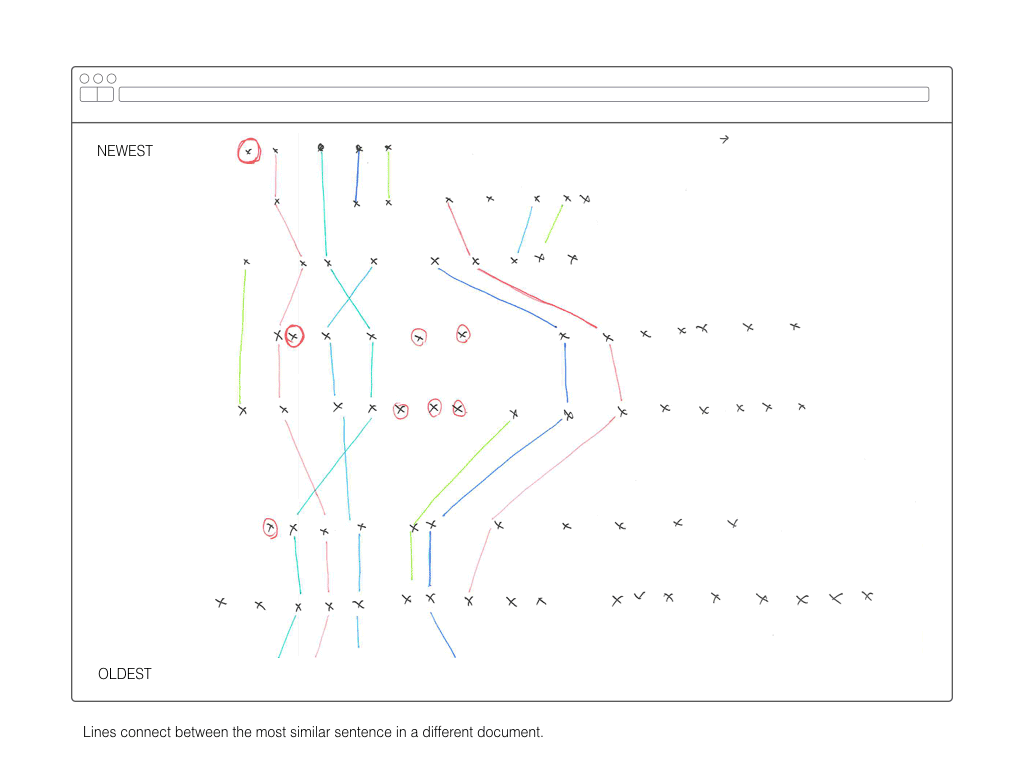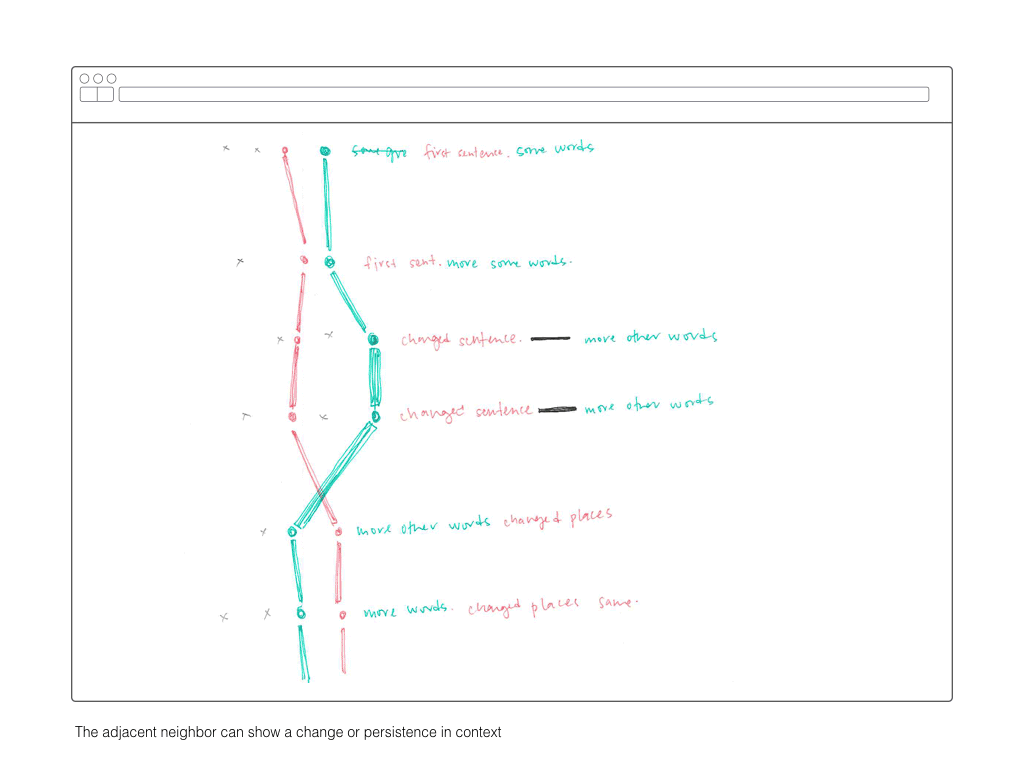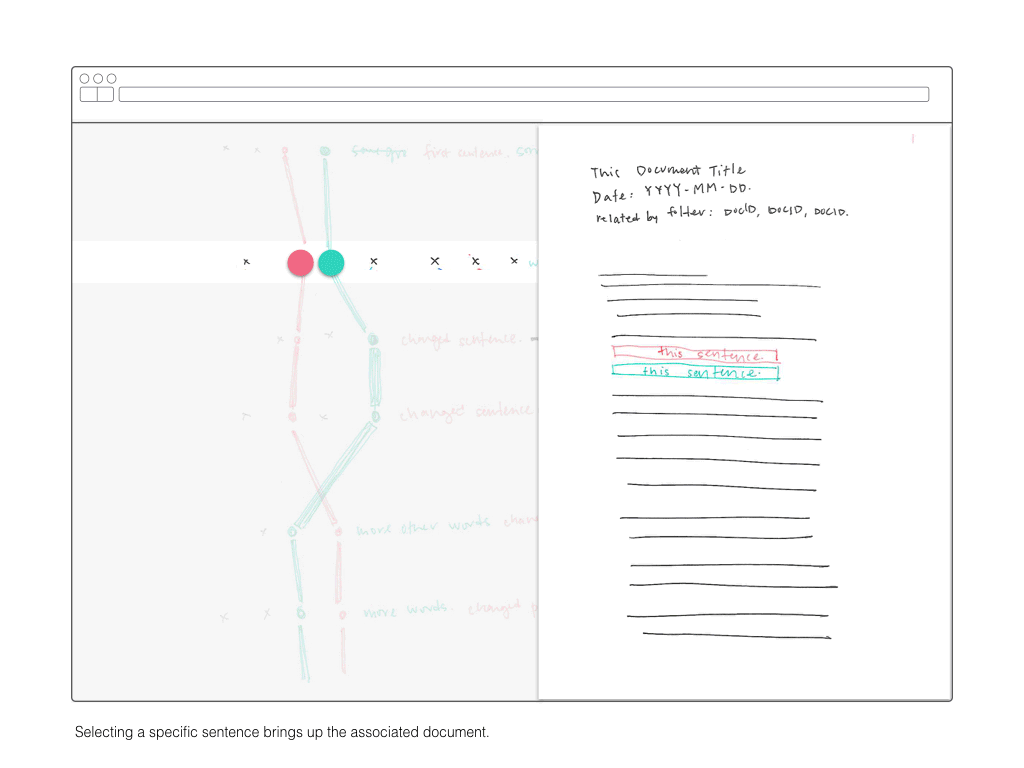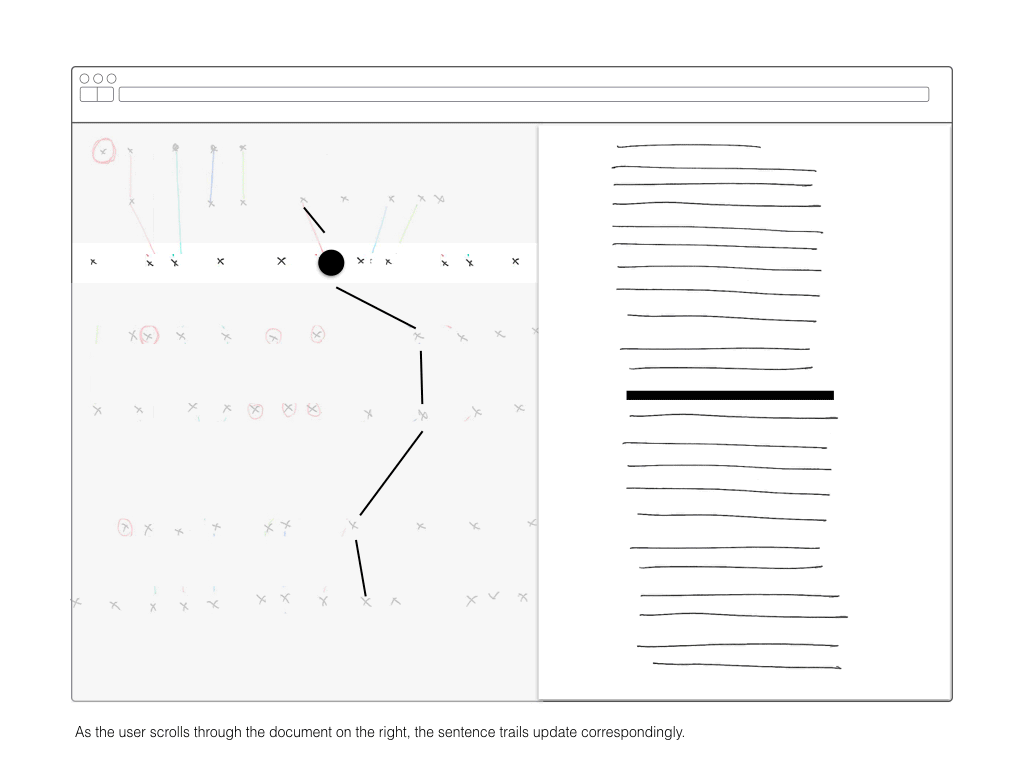
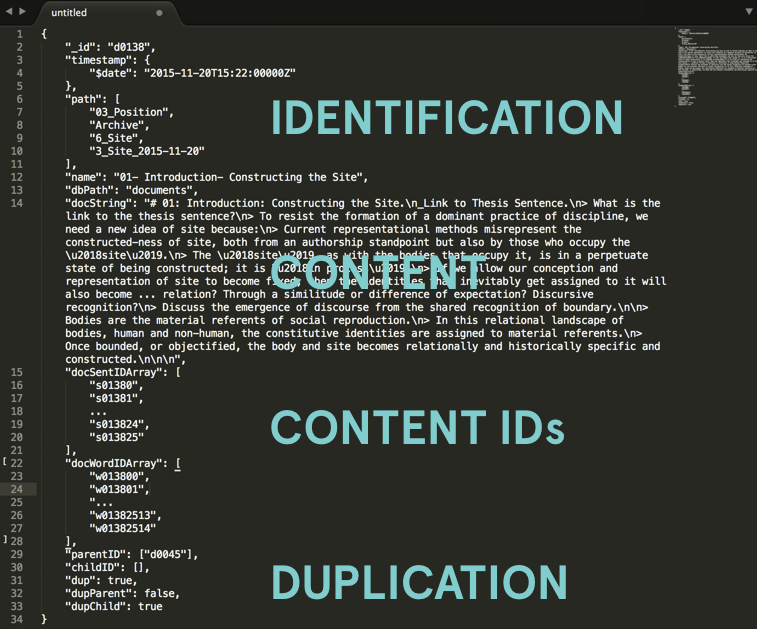
All documents were parsed into JSON objects, included time-based information about their creation, whether they were duplicates of other documents, and references to their subparts: sentences and words.

Similarity
Documents and sentences were compared using the dice-coefficient method of analysis which compares across bigrams within a string. It gives less weight than other methods to outliers and the beginning of a string.